Taking “Content First” Very Seriously

The new www.cloudfour.com site stretches content-first thinking to its academic extremes
Whereas my personal theme for the second half of 2011 was about letting content go, 2012 seems to be the year I obsess about content: what is content, what does it mean, and what does it look like? How do we go about untangling the CMS mess we’ve built over the last decade-and-a-half? How should content be marked up? Stored? Transformed? Delivered to devices and clients?
With the new Cloudfour.com site, we got a chance to Think Very Deeply about content and our mobile experience. We got to explore some of the nagging questions that keep us (well, me, at least) up at night. I’m not going to profess to have the answer, nor am I going to assert that the (long) thinking, designing and development process we endured was without convulsions or struggle1. But I think we’ve been lucky in the opportunity to dig in.
Content is content is content is content…
At its core, www.cloudfour.com is content. Human-readable content written by regular people. Being bold and brave (maybe it’s hubris), we started with content before any design happened.
We’re not, by far, the first to shout, “Hey, Content First!” That notion’s been around the block a few times. But the practical challenge lies in unmooring oneself from 15 years of executing web development and design in particular ways and trying new habits and processes on for size. What sounds straightforward—have a point first and then make it pretty—actually goes against a staggering amount of what we’ve become used to doing with our web projects.
In our case, we opted for writing and storing our content in static text files. We selected markdown for this project, specifically, pandoc-extended markdown with Cloud Four-specific post processing extensions. Phew. More on that sometime other than now. Important piece being: human-readable text in a loose but meaningful format.
What a transformation!
Our happy, respected content sits there on the filesystem, grinning mysteriously, versioned, simple, ready to serve whatever purpose it needs to serve. In our case, obviously, we want a web site, so we can transform that core content into a set of web pages to make up a site that works in web browsers.
You’ll note that a lot of this sounds like, um, duh, yeah, we’re web devs, we make web sites. But in peeling back and thinking this hard about content, web pages as HTML isn’t necessarily a given for every context that we might use this content. But let’s talk about web pages for our purposes today.
Our content is transformed using a somewhat magical tool called pandoc2, which processes it, plunks it in an HTML template and does some other miscellaneous things—out come HTML pages! These HTML pages are then pushed to the live server environment where they enjoy a performance-tuned, simple existence, just waiting for folks to look at them and enjoy their content.
Though the content changes from time to time—it’s versioned in a github repository—it isn’t actually dynamic, so serving it out of a database (here I am getting a bit pedantic again) provides more of a performance-maintenance drain than a boon. Or at least, that’s what I tell myself to feel awesome.
But what about the blog? Ain’t broke, don’t fix
As giddy as the simplicity of static content and transformations and a pure ultra magical shared philosophical language of core content makes me as a dev, I have to kneel to practicality and things that make sense sometimes.
WordPress is a blogging framework. It’s been around a long while, we’ve used it a long while, and it has the tools for, well, you know, blogging. We’re sticking with WordPress for our blog, though you may notice that our blog now lives a robustly independent existence as blog.cloudfour.com. Heck, maybe I’ll get the exciting opportunity to futz around with partially-static WordPress options with John!
There’s a lot more to talk about
The site is intensely responsive. It uses some edgy CSS selectors to get its job done semantically. The process of separating content from presentation can be deeply, deeply hard and we have stuff to say about that. We’ve spent a lot of time optimizing performance. We’ve battled specific bugs (many we knew about, some we didn’t) to get the site to look reasonably decent across a lot of devices. We are doing unprecedented things with :before pseudo elements. Our media queries are in ems.
We’ll continue to talk about the specific cool stuff we experimented with to get the new site working in upcoming posts. But I wanted to give a quick, high-level look at what we did before getting lost in the details.
Here is a nice picture
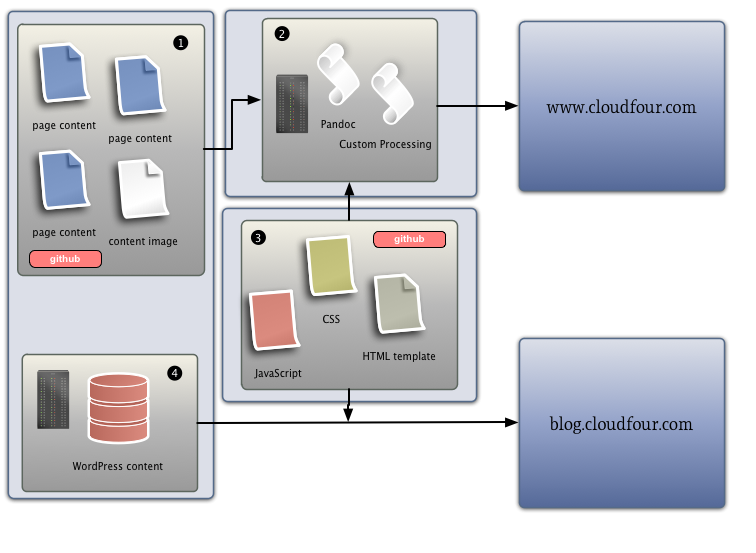
- Static content pages and image content, managed in a github repository.
- Pandoc and other transformation processing.
- Layout, design and behavior resources shared between static web and our blog.
- Blog content stored in WP database.
Thank you, Cloud Four Team
I owe a great amount of gratitude to the brilliant team at Cloud Four. Thinking the new site through and building it wasn’t always easy, fun or even sane. We had to (uncomfortably) learn new ways to do things that we were quite competent at before thankyouverymuch. There were confounding moments. It took John 327 hours or whatever to get Haskell compiled3 on our shared development server so we could run pandoc. And Aileen endured my weird experiments with SASS.
- Sometimes there was downright silliness as I pushed to explore the pedantic edges of what we could pull off with just content
- Not actually magic, but written in Haskell, which is kind of the same thing to my inadequate brain. More about pandoc here.
- Not actually true. But it did take John quite some time—it was hard! So, thank you, John.

